
Large language models are increasingly used to help people shop online. They suggest products, compare options and explain why something might be a good choice. But which model is actually best at this?
Recent research from ByteDance suggests that ChatGPT currently performs best for shopping tasks, especially when used with its DeepResearch tools.
This article breaks down what the research tested, how it was evaluated, and what the results really tell us.
The Research Methodology and Why This Study Is Different
Most earlier research on LLMs and shopping focuses on language quality or reasoning in isolation. These studies often rely on small, closed datasets or simplified product lists. In many cases, models never have to deal with real products or real constraints.
This study takes a very different approach.
The benchmark, called ShoppingComp, was created by a research team at ByteDance to evaluate how well large language models handle real shopping decisions, not idealised examples.
The researchers built over a thousand realistic shopping scenarios based on 120 core tasks. These were designed and checked by human experts to reflect how people actually shop.
Each task involved real products and practical constraints. These included budget limits, compatibility requirements, safety concerns, and specific use cases. A recommendation could fail even if it sounded reasonable, for example if it missed a safety requirement or a key compatibility detail.
Crucially, the benchmark separates skills that are often grouped together. It evaluates product correctness, constraint coverage, safety, and explanation quality independently. This makes it much harder for a model to score well through fluent language alone.
As a result, the benchmark exposes weaknesses that earlier evaluations often miss, particularly around missed requirements and overconfident explanations. At the same time, it offers a clearer and more realistic picture of how close AI systems are to being genuinely useful for shopping.
How the Models Were Evaluated
The study uses four main evaluation criteria.
Answer Match measures whether the model selected the correct product. This turned out to be the hardest part for every model tested.
Scenario Coverage checks whether all user requirements were met. A recommendation could sound reasonable but still fail if it missed a key constraint.
Safety-oriented Performance looks at whether models avoid unsafe or inappropriate recommendations.
Rationale Validity measures whether the explanation is factually correct and logically sound. Fluent writing is not enough. The reasoning has to be right.
Together, these metrics give a clear picture of whether a model can be trusted in a shopping context.
Results Across the Models
Model | Answer Match F1 (%) | Scenario Coverage F1 (%) | SoP (%) | Rationale Validity (%) |
|---|---|---|---|---|
ChatGPT DeepResearch | 18.17 | 92.67 | 62.06 | 83.33 |
GPT-5 | 11.22 | 91.73 | 50.13 | 90.30 |
Gemini DeepResearch | 9.58 | 86.93 | 45.46 | 87.84 |
Gemini 2.5 Pro | 7.73 | 85.13 | 47.79 | 83.55 |
Claude 4 Opus | 6.74 | 88.68 | 35.13 | 77.28 |
DeepSeek V3.1 (with thinking) | 5.71 | 79.59 | 37.00 | 81.08 |
Claude 4 Sonnet | 3.60 | 89.31 | 20.65 | 78.51 |
Gemini 2.5 Flash | 3.92 | 62.16 | 22.71 | 81.08 |
GPT-4o | 2.59 | 67.43 | 39.09 | 73.07 |
How to Read These Results
Answer Match F1 shows how often a model selects the correct product. This remains the hardest challenge. Even the best-performing system stays below 20 percent, which shows how difficult real-world shopping decisions are for AI.
Scenario Coverage F1 measures whether all user requirements are met. Many models score highly here, which suggests they are getting better at tracking multiple constraints at once. However, strong coverage does not always mean the right product was chosen.
SoP (Safety-oriented Performance) captures how well models avoid unsafe or inappropriate recommendations. This is a critical metric for shopping. Scores vary widely, showing that safety is still an uneven capability across models.
Rationale Validity reflects how accurate and grounded the explanation is. GPT-5 stands out here, producing explanations that are close to expert-level quality.
Who Performs Best Across the Key Benchmarks
ChatGPT leads across the two most important benchmarks, Answer Match and Scenario Coverage. Together, these metrics show how often a model surfaces the right products and correctly addresses the user’s requirements in the prompt.
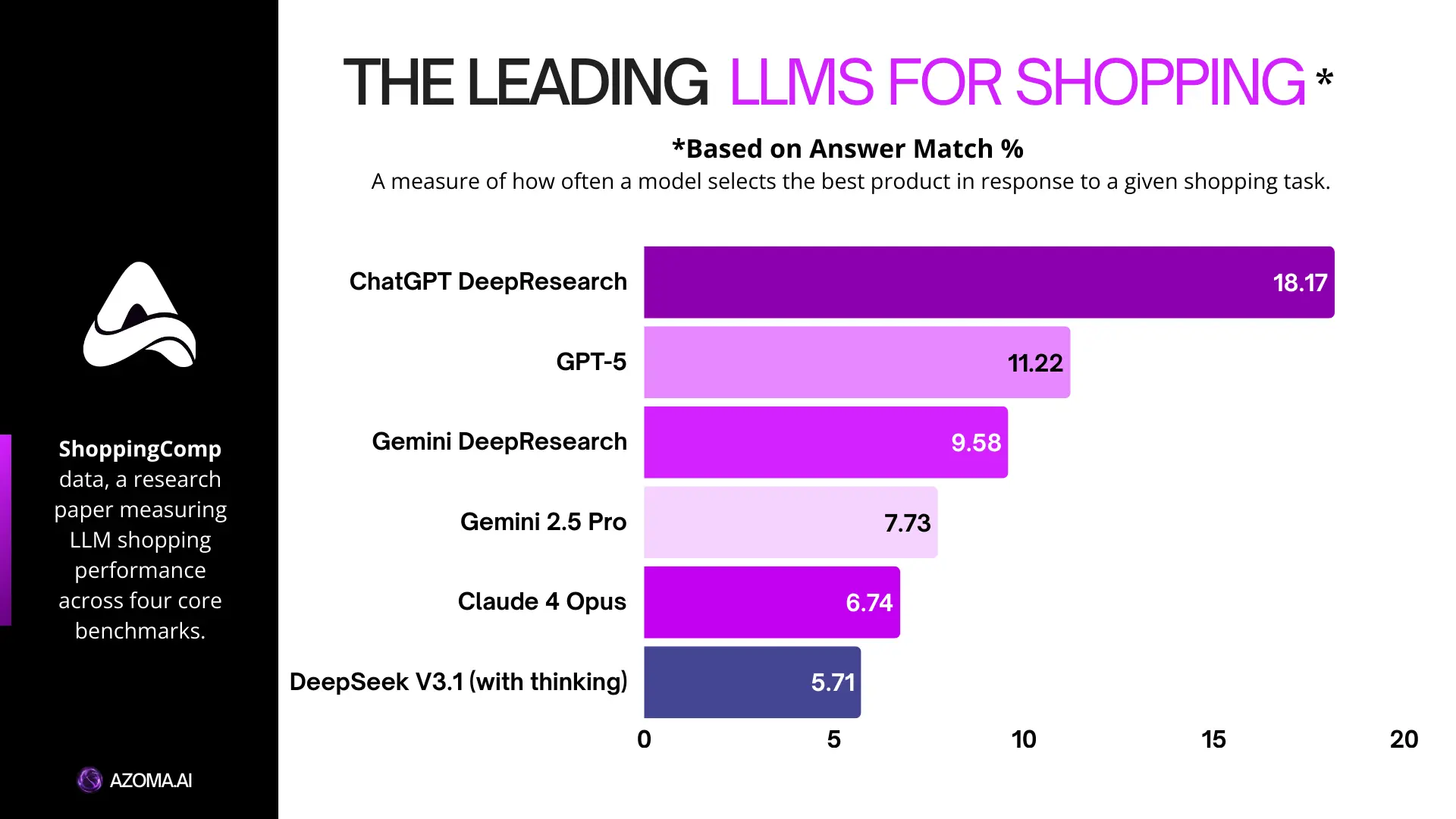
Gemini ranks second on Answer Match, suggesting it is relatively strong at finding relevant products, even if it is less consistent overall. Claude models, on the other hand, perform better on Scenario Coverage, placing second on this metric and showing strength in tracking and responding to complex user requirements.
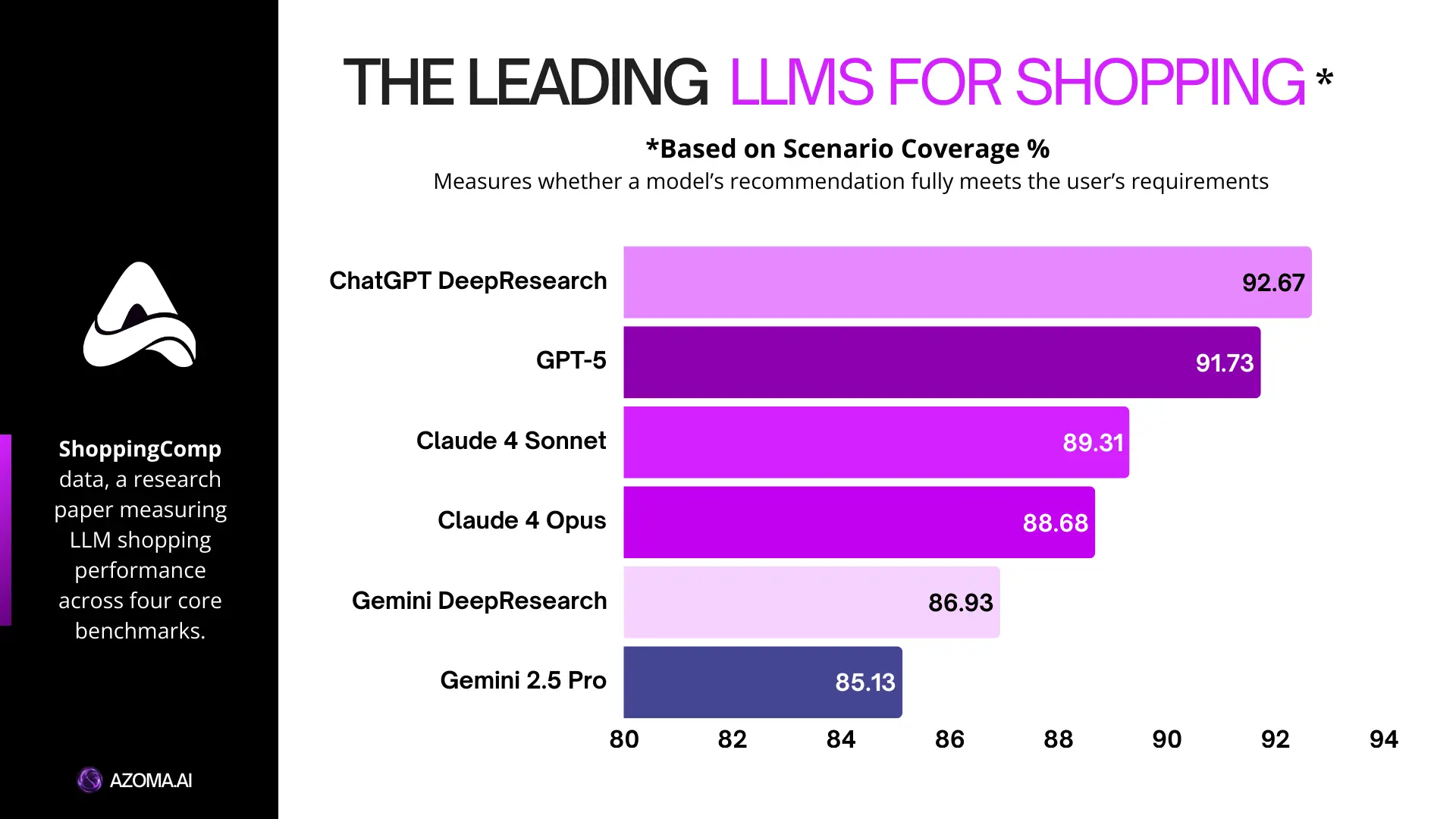
This split highlights an important pattern. Some models are better at finding the right products, while others are better at reasoning through constraints. The strongest shopping systems are those that can do both well at the same time.
What Stands Out
The clearest takeaway is that AI shopping systems are becoming more balanced and trustworthy, especially when safety is considered alongside accuracy. ChatGPT DeepResearch leads not just on product matching and coverage, but also on safety. Its strong SoP score suggests that research-enabled systems are better at avoiding harmful recommendations, not just finding plausible ones.
GPT-5’s results are particularly encouraging for the future. It delivers the strongest explanations and performs well on safety, even without external research tools. This suggests that the reasoning layer is largely in place. As retrieval and checking improve, models like GPT-5 are well positioned to close the remaining gaps.
The results also point to steady progress in handling complex and realistic requirements. High Scenario Coverage scores across several models show that modern LLMs can track multiple constraints at once. Combined with improving safety performance, this makes them increasingly suitable for real shopping use cases.
Most importantly, the gap between standalone models and research-enabled systems highlights a clear path forward. The strongest performance comes from systems that combine structured data, search, and reasoning. As these systems become more integrated, we should expect improvements not just in accuracy, but in safety and reliability as well.
Taken together, the findings suggest that AI shopping is not solved yet, but it is clearly moving in the right direction. With better system design and continued model improvements, the gap between AI-assisted and human shopping decisions is narrowing.
Beyond General-Purpose LLMs: Rufus & Sparky
It is also worth noting what this research does not include. The benchmark focuses on general-purpose LLMs and research-enabled systems, but it does not evaluate purpose-built shopping models developed by large retailers.
This includes models like Amazon’s Rufus and Walmart’s Sparky, which are trained and integrated directly into retail platforms. These systems benefit from deep access to product catalogues, inventory data, and user behaviour, which can give them advantages in real-world shopping contexts that general models do not have.
That said, this omission does not weaken the findings. Instead, it highlights an important distinction. General-purpose LLMs are improving rapidly, while retailer-built models point to a parallel path where tight integration with commerce data drives performance. The most effective future shopping experiences are likely to borrow ideas from both approaches.
Why Brands Need to Understand Their Visibility in LLMs
This research shows that AI shopping is maturing fast. Large language models are getting better at handling real requirements, explaining decisions, and avoiding obvious errors, especially when paired with structured data and search.
As these systems become part of everyday purchasing, visibility inside LLMs will matter as much as traditional search or marketplace rankings. How a brand is represented inside these models will increasingly shape buying decisions.
Azoma helps brands understand how they appear inside large language models, so they can stay visible as AI-driven shopping becomes more common.
Get in touch with Azoma today to see how your brand shows up in AI-powered shopping.

Article Author: Max Sinclair