

The headlines treated it as a milestone. Carrefour became the first major European retailer to let shoppers build a grocery basket directly inside ChatGPT, giving France's estimated 26 million ChatGPT users the ability to plan meals, filter by dietary preference, and send a basket to checkout without leaving the chat interface. It is a genuine first. But the more important story is not the announcement.
The more important story is what happens inside the system: how ChatGPT actually decides which products it surfaces, which signals it reads, and which it ignores entirely. Because Carrefour will not be alone for long. The architecture it has deployed is a blueprint, and the brands that understand its mechanics now will be in a structurally different position when that blueprint rolls out across a dozen more retailers.
Azoma ran proprietary research across 50,000 sessions of the Carrefour GPT shopping app, testing multiple product categories. What we found was a three-layer selection stack with specific, reproducible signal weights that determine which products the AI shopping assistant recommends. This article breaks down that stack, explains what each layer means for brand visibility, and draws out the implications for every retailer integration that follows.
How Does the Carrefour ChatGPT Integration Actually Work?
The experience looks simple to the shopper: describe what you want, get a basket back. The technical architecture underneath is more structured. Product selection happens across three distinct layers, each controlled by a different party and each requiring a different optimization strategy.
Layer 1: The Retailer's System Prompt and Shopping Journey
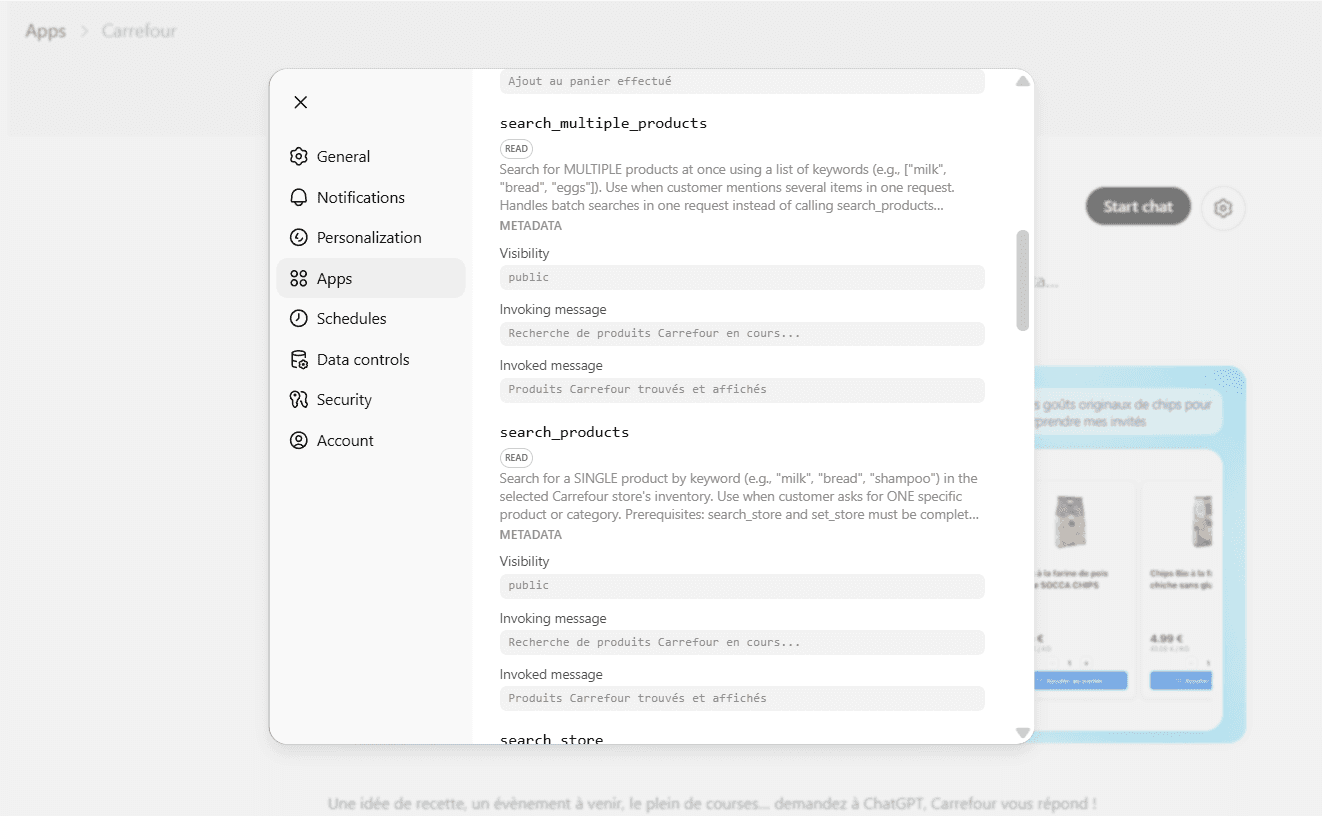
The session opens with a structured flow controlled entirely by Carrefour. The integration collects the shopper's delivery address and fulfilment mode first, which determines which store's inventory is queried and whether home delivery or click-and-collect SKUs are returned. The SKU set changes entirely based on this input. Brands with inconsistent availability across fulfilment modes will be invisible in certain sessions regardless of how well their listings are optimized.
The flow then collects meal context, group size, and stated priorities ("cheapest," "healthiest," "best value"). These inputs directly shape which products are recommended after a search occurs. A stated priority of 'cheapest' shifts the model's weighting toward price. An absence of any stated priority defaults to a 'simple default recommendation' mode, where suitability and defaultness carry the most weight.
Layer 2: Live MCP Search of the Retailer Catalogue
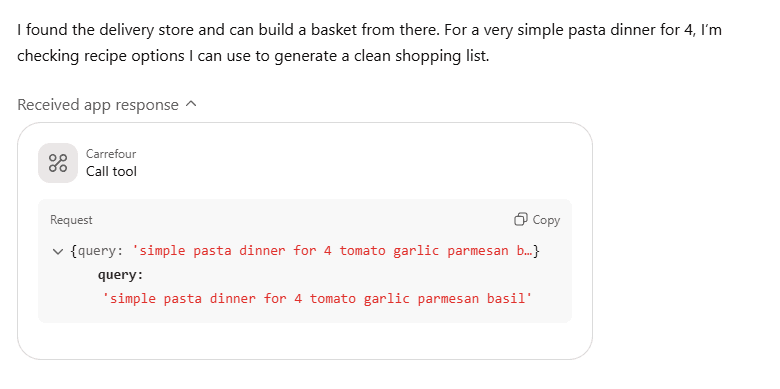
Once intent is established, ChatGPT executes a live keyword search of Carrefour's product catalogue via MCP, the Model Context Protocol standard for connecting AI agents to external data sources in real time. This is functionally equivalent to a shopper running a keyword search or selecting a simple category page, except the query (something simple like "pasta," or, "shampoo," is generated by the AI from the user's conversational input. If the user has a recipe in mind - let's say a simple pasta dinner - multiple searches are run for relevant ingredients.
The biggest indicator that keyword/category search is used during the MCP catalogue call is the that recommended product order is consistent 80% of the time when running default category specific searches.
The critical implication: if a product does not appear in the MCP search results for the keyword the AI generates, it does not exist to the model. Azoma's research suggests the feed is live keyword search rather than a pre-curated catalogue, meaning product listing page presence for the relevant search terms is a hard gate. Products that do not rank in the on-site search results for the AI's generated query never enter the consideration set, regardless of how well optimized their listing copy is at the ranking layer.
Layer 3: ChatGPT's Own Reranking Criteria
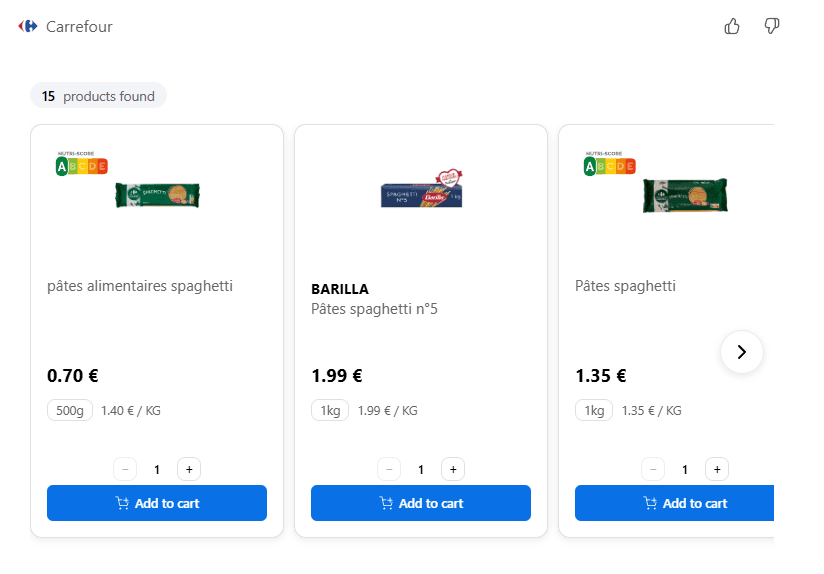
After MCP retrieval delivers a set of candidate products, ChatGPT applies its own reranking logic. This is the layer that the system described explicitly when asked directly what it looks at. A weighing rubric was devised by how often each criteria was provided as a reason for recommending a product:
Criterion | Approx. Weight | What This Means for Brands |
Suitability (meal/use-case fit) | ~35% | Pack size, format, and use-case alignment with the shopper's stated need (e.g. 1kg pasta for 4 people vs. 500g single-serve) |
Defaultness (is this the obvious choice?) | ~30% | Whether the product is the standard, recognizable format in its category. Specialty descriptors (bio, sans gluten, rapide) actively penalize ranking for generic requests. |
Value (price relative to category peers) | ~25% | Price per kg inferred, not read from a structured field. Position relative to category pricing floor matters more than absolute price. |
Brand confidence (recognizability) | ~10% | Whether the model recognizes the brand from its training data. Not a retailer-side field. Drawn from brand presence on the open web. |
Disclaimer: These weights were self-reported by the GPT during testing
What Data Fields Does ChatGPT Actually Read From a Listing?
One of the most practically useful findings from the research was getting the system to specify, field by field, what it has access to and what it does not. The contrast matters because many brands are optimizing fields the model cannot read, while neglecting the ones it is actively using.
Data Field | Used? | Notes |
Product label / title / description | YES | Primary signal. Brand name, format descriptors, and specialty language all read from here. |
Brand (inferred from label) | YES | Not a separate field. Brand name visible in title used as a weak tie-breaker for brand confidence weighting. |
Pack size / format | YES | Used to infer suitability for stated meal size. 1kg ranked above 500g for a group of 4 with no stated priority. |
Price | YES | Price per kg inferred, not read from a structured field. Relative to category peers, not absolute. |
API result position | YES (weak) | Raw MCP result order used as a weak relevance signal when other criteria are equal. PLP ranking matters. |
Specialty descriptors in title / description | YES (penalty) | e.g. bio, sans gluten, rapide, plat. Actively penalizes ranking for generic requests. Reversal only when user has stated that preference. |
Customer ratings / reviews | NO | Confirmed not available in the API response. |
Sponsored / promo flags | NO | Not visible. Whether upstream results are commercially influenced is unconfirmed. |
Ingredients / nutrition (structured) | NO | Not available in tool output. |
Sales velocity / conversion | NO | Not available. The model has no visibility of commercial prioritisation upstream. |
From the data, PDP leverage exists in title and description, where contextual use case language is most important. This is very similar to Amazon Cosmo optimization - which is contextual in nature, as is highlighted in this Amazon white paper.
Specialty descriptors are a double-edged lever
The model actively penalizes titles containing specialty descriptors (organic, gluten-free, quick-cook, dish) when the user has not stated a preference for those attributes. The same descriptors become positive signals the moment the user specifies them.
This means brands with specialty positioning face a trade-off: optimize for the specialty request, and you rank below the fold on generic ones. Generic titles capture broad intent but lose specificity searches.
Keyword presence in the title determines inclusion, not just rank
Because the MCP layer searches the catalogue by keyword, and the model generates that keyword from the user's conversational input, a product that does not appear in the keyword search results for the AI's inferred query is not in the ranking pool at all. This is not a ranking penalty. It is an exclusion.
The practical test: for every product category you care about, run the search terms a shopper might use conversationally and check whether your products appear in the Carrefour search results for those terms. If they do not, listing copy and title optimization are downstream problems. PLP presence for the relevant search vocabulary is the first gate.
Why Does Brand Recognizability Matter in an AI Ranking System?
Brand confidence accounts for roughly 10% of the self-reported weighting rubric, which makes it the smallest of the four criteria. But it is also the most structurally novel, because it is the only signal that originates outside the retailer's system entirely.
When the model weighs brand confidence, it is not reading a field from the Carrefour product feed. It is applying a prior derived from its training data: from press coverage, product pages on brand websites, review content, social mentions, and any other signal about the brand that appeared in the corpus the model was trained on. A brand with stronger, more consistent representation on the open web arrives at the reranking layer with a head start that private-label and less-established challengers cannot replicate through listing optimization alone.
This creates a compounding effect. Brands that invest in structured product data across their own domains, consistent brand information, and media presence are not just doing marketing. They are improving a ranking input inside closed retail AI systems they will never have direct access to. The web is now a feed that shapes in-store AI recommendations.
You can watch our Head of PR, Ella Macdonald, discuss how PR effects AI visibility at our London Agentic Commerce Decoded Conference here:
Does This Transfer Beyond Carrefour?
The Carrefour integration is notable for being first in Europe. MCP is the same protocol that underpins how AI agents connect to external data sources across systems. Carrefour backed Google's equivalent Universal Commerce Protocol standard in early 2026, which is designed to enable the same interoperability across Google's AI-powered shopping environments. Interestingly, OpenAI's Agentic Commerce Protocol is not used by the Carrefour app - instead a shopping cart module is provided, which can be sent to Carrefour.fr to purchase on their site.

Similarly, the Target integration was the first in North America, serving the purpose of quote: "Target's app provides a curated, conversational shopping experience right within ChatGPT. It allows shoppers to ask for ideas, browse and build multi-item baskets, shop for fresh food, and check out using their choice fulfillment options — including Drive Up, Order Pickup, and Shipping. For example, a guest can tag the Target app in ChatGPT and say, “Help me plan a family holiday movie night,” and instantly get curated ideas — cozy blankets, candles, snacks, slippers, and more. They can browse the options, build the perfect basket, and check out through their Target account. And soon, Target will add new features like Target Circle linking and same-day delivery."
Other major European grocers are watching the Carrefour rollout closely. The difference between now and twelve months from now is that the three-layer stack described in this article will be running across multiple retail environments simultaneously, each with its own system prompt and user flow, but each using the same fundamental architecture for catalogue retrieval and GPT-side reranking.
The Azoma research was conducted on a single retailer's implementation. But the reranking criteria observed, including the field-level signals the model reads and ignores, the specialty descriptor penalty, the pack-size inference logic, and the brand confidence weighting, are GPT-level behaviors, not Carrefour-specific configurations. A brand that optimizes for this stack on Carrefour is likely also optimizing for Target, Tesco, Auchan, and every other retailer that builds on the same underlying model and protocol.
What Should CPG Brands do with This Information?
The research findings point to three concrete priorities. They are ordered by urgency, not by complexity.
1. Audit on-site keyword presence for AI-generated search terms
Run the searches an AI agent would generate for your categories. Use conversational phrasings, meal-context phrasings, and group-size phrasings. Check whether your products appear in the PLP results. If they do not, you are outside the MCP retrieval pool before any ranking logic applies. This is your highest-leverage problem to fix and it requires the same toolkit as traditional storefront SEO: title structure, category tagging, and keyword consistency.
2. Rebuild title strategy around AI readability, not human skimming
Audit your product titles for how a language model will parse them, not how a human skimming a shelf would read them. Is pack size stated explicitly? Is the format descriptor standard and unambiguous? Are specialty qualifiers present when they should not be for generic queries? The title is the primary field the model reads for most of the signals it uses. Every word in it carries even more weight than in a traditional search environment.
3. Treat your open-web brand footprint as a ranking input
Brand confidence in the GPT reranking layer comes from training data, not from retailer feeds. Structured product data on your brand domain, consistent brand information across channels, media coverage, and review presence are now functional inputs to AI recommendation quality inside closed retail systems. This is not a new argument for brand investment. It is a new data point for quantifying its commercial return.
How Azoma Helps Brands Optimize for This Stack
Azoma builds AI visibility software for ecommerce and CPG brands. Our AMP (Agentic Merchant Protocol) is a product information layer designed specifically for the agentic commerce stack. It structures and optimizes product data for the environments where AI agents make retrieval and ranking decisions, including Google UCP, OpenAI ACP, and the MCP-based catalogue connections that underpin integrations like Carrefour's.
AMP helps brands ensure their product data is structured correctly for AI retrieval, that their titles are optimized for the signals that AI agents actually read, and that their catalogue infrastructure is compatible with the MCP connections that retailers are building. It also enables brands to build MCP-compatible infrastructure on their own catalogues, which becomes relevant as the number of retailer AI integrations grows and brands need to maintain consistent optimization across multiple touchpoints simultaneously.
Final Thoughts
The Carrefour ChatGPT integration is a proof of concept for something larger: a commerce layer where AI agents make selection decisions on behalf of shoppers, drawing on catalogue data, conversational context, and their own training-derived priors. The shelf has moved. It now exists inside a conversation.
Brands that understand the new selection stack, what signals the model reads, which it ignores, and where its ranking decisions originate, are in a position to act before the pattern becomes standard across retail. Those that treat this as a Carrefour story rather than a structural shift will be optimizing for the wrong environment when the next integration launches.
Azoma's AMP is built for this stack. Talk to us about benchmarking your catalogue against the signal framework that AI shopping assistants actually use.
Methodology note: Azoma's research was conducted across 50,000 sessions of the Carrefour ChatGPT shopping integration in April 2026, testing multiple product categories. Some findings, particularly around mode confirmation and product search behavior, may reflect a degraded tool state rather than fully intended functionality. Ranking criteria weights were self-reported by the GPT and have not been independently validated against actual output at scale. All findings should be treated as directional and replicated before use as the basis for listing strategy changes.

Article Author: Max Sinclair